[RDBMS의 문제점]
서버를 구성할 때 데이터베이스는 주로 RDBMS를 사용해 운영한다.
서버의 용도에 따라 다르겠지만 구글이나 네이버 같은 매우 많은 사람들이 사용하는 규모가 된다면
데이터베이스도 포화상태가 될 것이고 쿼리를 하나 실행하는 데에도 많은 시간이 들어갈 것이다.
실제로 공공데이터 포탈에서 2000만 Cardinality 규모의 데이터를 받아 샘플 DB를 생성하고 조회해보면 Index를 걸어놓았음에도 불구하고 20초가 넘게 걸린다.
간단한 조회 쿼리가 아니라 다양한 조건이 걸리고 몇 개의 테이블이 조인되면 더 오래 걸릴 것이다.
[데이터베이스 데이터 캐싱]
DB를 튜닝하고 다원화하고 좀 더 효율적으로 인덱스를 걸 수도 있겠지만 가장 근본적인 문제인 RDBMS로의 쿼리 전송을 줄이는 방법도 있을 수 있는데 데이터 캐싱을 통해 어느 정도 쿼리 전송을 줄일 수 있겠다.
데이터베이스에서의 데이터 캐싱이란 처음 쿼리를 전송할 때는 데이터베이스에서 직접 가져오지만 두 번째 쿼리부터는 캐시에 저장된 데이터를 가져와 데이터베이스까지 직접 쿼리를 전송하지 않아도 된다.
주로 데이터베이스에서 캐시용으로 NoSQL 류의 Redis나 Memcached를 사용한다.
두 DB 모두 디스크 기반이었던 기존의 RDBMS 들과 달리 메모리 기반이며 성능을 목적으로 개발되었기 때문에 캐시 서버로 주로 사용된다.
(메모리 캐시라는 공통점 이외에는 다른 점이 더 많은 Redis와 Memcached이다.)
가장 기본적이고 단순한 Key-Value 형태로 메모리에 저장하고
또한 내부적으로도 성능에 목적을 둔 기능들이 많기 때문에 데이터 캐시 서버로 사용하기 매우 좋다.
메모리 캐시는 잘못 사용하면 성능이 더 안 좋아질 수도 있다고 한다.
보통 캐시에 들어갈 데이터는 자주 사용하는 데이터 위주로 저장해야 하고,
읽기는 많지만 쓰기는 적은 데이터 그리고 데이터의 양이 많지 않은 데이터를 캐싱 하는 것이 적합하다고 한다.
또한 캐시에도 데이터가 쌓이면 언젠가는 RDBMS와 다를 게 없어지므로 적절한 데이터 캐시 만료 기간을 설정해야 한다.
[데이터 캐싱이 적용된 시스템에서 CRUD]
캐시 서버가 사용되는 데이터베이스 시스템 구성도는 시스템 상황, 용도, 설계자의 캐싱 전력에 따라 달라질 수 있고 매우 다양하게 구성될 수 있으나 나는 가장 기본적인 개념을 설명하기 위해 DB 서버와 캐싱 서버 하나만 둔다.
(캐싱 전략에도 방법론이 있고 공부할게 많다.)
- Read

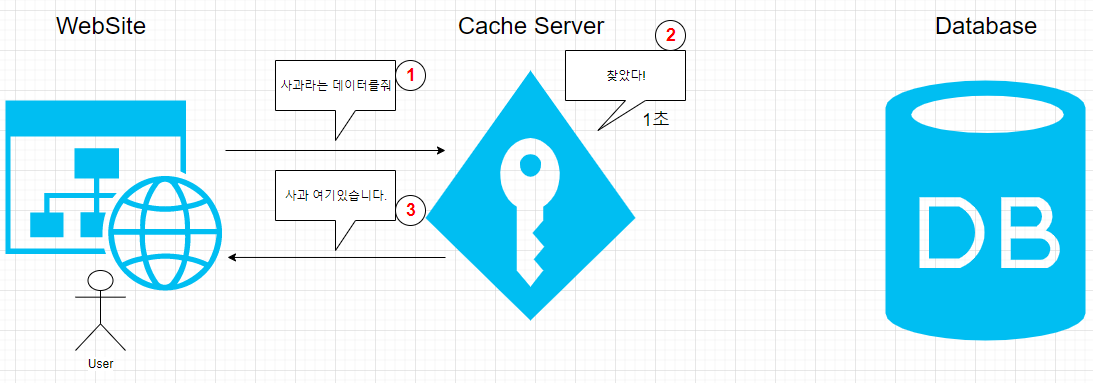
- Create : Database에 데이터를 생성한다.
- Update : Datebase에 데이터를 수정하고 캐시서버에도 데이터가 있다면 마찬가지로 수정한다.
- Delete : Database에 데이터를 삭제하고 캐시서버에도 데이터가 있다면 마찬가지로 삭제한다.
물론 캐싱이 만능은 아닐 것이다. 비용도 비용이지만, 제대로 사용하지 못하면, 최신으로 업데이트되지 않은 “틀린” 데이터를 클라이언트에게 제공할 수도 있고 비용이 최적화되지 않을 수도 있다.
가장 중요한 건 기존의 시스템에 정확히 어떤 부분에서 성능이 저하되는지를 주안점으로 두고 그에 대한 대처를 가장 효율적으로 하는 것이 좋지 않을까 싶다.
'데이터베이스' 카테고리의 다른 글
| How to create RESTAPI using DreamFactory (0) | 2020.03.23 |
|---|---|
| [Redis] Bloom Filter (0) | 2020.01.31 |
| [Redis] HyperLogLog (0) | 2020.01.22 |
| [hiredis] Using redis Database in C (0) | 2020.01.17 |
| Can't connect to MySQL server on 'address' (10061)' (0) | 2020.01.16 |