Microservice Architecture (MSA)
- 하나의 어플리케이션을 여러개의 작은 서비스 유닛으로 구성
Pros
- 각각의 독립적 서비스로 개발과 배포가 빠름
- 서비스 장애의 경우 전체 시스템에 영향을 주지않음
- 서비스마다 다른 기술스택을 가질 수 있음
Cons
- 각 서비스간 통신 비용 증가
- 개별 서비스간의 내부 통신 복잡성
- 통합 테스트 및 배포의 어려움

Monolithic Architecture
- 하나의 어플리케이션에 모든 구성요소가 통합되어 하나처럼 움직임
Pros
- 소규모 프로젝트에 적합
- 개발 / 빌드 / 배포 / 테스트가 용이
Cons
- 프로젝트 규모가 커질수록 빌드 배포 시간이 길어짐
- 작은 수정에도 프로젝트 재배포 필요
- 일부의 오류가 시스템 전체에 영향
- 한 종류 기술스택에 국한
MSA on Robotics
- 모듈화되어 여러 컴포넌트가 하나의 시스템으로 동작하는 로보틱스 특성상 MSA가 적합
- 로보틱스의 각 기능을 개별 서비스로 분리하면, 필요한 부분만 독립적 확장 가능
- ex) SLAM 서비스가 높은 연산량을 요구할 경우 SLAM 컴포넌트만 스케일링하여 성능 최적화
- 서비스별로 최적의 기술스택 사용 가능
- ex) SLAM(C++) / perception(Python) / data logging(Go)
- 하나의 서비스가 실패해도 전체 시스템이 중단되지 않도록 설계(Fault Tolerance)
- ex) perception 서비스가 다운되도, navigation 기능은 유지
- 분산 환경 및 클라우드 연계
- 일부 서비스는 로컬에서 실행하고, 일부는 클라우드에서 활용(navigaion - local / data analysis - cloud)
- 개발 생산성 향상 및 협업 용이
- 컴포넌트 단위로 나누어 병렬 개발
- CI/CD를 적용하여 빠르게 배포 및 테스트
MSA on Robotics 예시
| 서비스 | 설명 | 기술스택 |
|---|---|---|
| SLAM | 실시간 환경 매핑 및 로컬라이제이션 | GMapping, OpenCV |
| Navigation | 목표 위치까지 이동 제어 | Dijkstra, A*, DWA |
| Perception | 객체 인식 및 추적 | YOLO, TensorFlow, OpenCV |
| Telemetry | 센서 데이터 수집 및 모니터링 | MQTT, Prometheus, Grafana |
| Cloud Integration | 클라우드에 데이터 업로드 | AWS IoT, Google Cloud |
Monolithic Architecture on Robotics의 문제점
- 다양한 센서, 액추에이터, 제어 알고리즘을 포함하므로 코드가 거대해지고 관리가 어려움
- 하나의 모듈을 변경할 경우 전체 시스템을 재배포해야 함
- 새로운 기능 추가 시 기존 코드와의 종속성이 증가
ROS와 연계
- ROS2는 기존 ROS1보다 마이크로서비스 구조에 적합
- DDS (Data Distribution Service) 사용하여 비동기 통신 지원
- 노드 기반 설계를 통해 독립적인 서비스로 구성 가능
- 컨테이너화하여 Kubernetes 기반 로봇 시스템 구축 가능
마이크로서비스 도입 시 고려할 점
서비스 간 통신 방식 결정
- gRPC → 고속 바이너리 통신, 경량 로봇 시스템에 적합
- REST API → HTTP 기반, 클라우드 연동 용이
- MQTT → IoT 및 저지연 데이터 스트리밍에 적합
- ROS2 DDS → 실시간 로봇 시스템에 최적
오케스트레이션 관리
- Kubernetes 사용 시 로봇의 Edge 컴퓨팅 환경과의 적합성 검토 필요
- Docker Compose를 이용하여 경량화된 마이크로서비스 구성 가능
데이터 처리 및 저장소 설계
- 센서 데이터와 로깅 데이터를 적절히 분리하여 관리해야 함
- 실시간 데이터는 Redis, 장기 저장 데이터는 PostgreSQL/MongoDB 사용 고려
MSA 기반 로보틱스 시스템
1. 물리 계층 - 리소스의 효율적 관리 및 확장성 제공
- 서버, 스토리지, 네트워크 등의 자원을 관리
- 퍼블릭 클라우드 (IaaS) 기반이거나 프라이빗 클라우드로 구축 가능
- OpenStack을 이용해 리소스를 가상화하고 동적 할당 수행
- Docker 컨테이너를 통해 리소스 격리 및 배포
- Kubernetes(k8s) 를 사용하여 자동화된 운영 및 유지보수 관리
2. 통신 인터페이스 계층 - 로봇과 클라우드 간의 데이터 통신을 담당
- Ubuntu 운영체제 및 개발 도구를 사전 설치
- ROS (Robot Operating System) 통합 → 로봇과 클라우드 간의 원격 통신 지원
- ROS의 토픽(topic) 기반 통신 방식을 활용하여 모듈 간 결합도 감소
- 로봇과 클라우드 플랫폼의 ROS 버전이 일치하면 ROS_MASTER를 통해 원격 연결 가능
3. 마이크로 애플리케이션 계층 - 경량 RESTful 프로토콜 기반의 마이크로서비스 관리
- 주요 컴포넌트
- Zuul: API 게이트웨이 → 동적 라우팅, 모니터링, 부하 분산 수행
- Consul: 마이크로서비스 등록 및 발견 기능 제공
- Ribbon: 클라이언트 측 부하 분산 → AWS 환경에서 중간 계층 서비스 관리
- Message Bus: 마이크로서비스 간 메시지 통신 담당
- Config Center: GitHub 등의 저장소에서 설정 파일을 관리하여 배포 및 유지보수 간소화
4. 비즈니스 계층 - 로봇이 필요로 하는 다양한 소프트웨어 및 데이터 처리 서비스 제공
- 자율주행 관련 서비스: 자율 주차, 자동 추종, 차선 유지 등
- 기본 클라우드 서비스: 오프라인 연산, 데이터 저장, 지도 생성 등
- 클라우드에서 센서 데이터를 수집 → 이종 데이터 융합, 머신러닝, 분석 수행
- 분석된 데이터는 다른 로봇과 공유되어 더욱 효율적인 자율주행 지원
로보틱스 시스템의 CI/CD
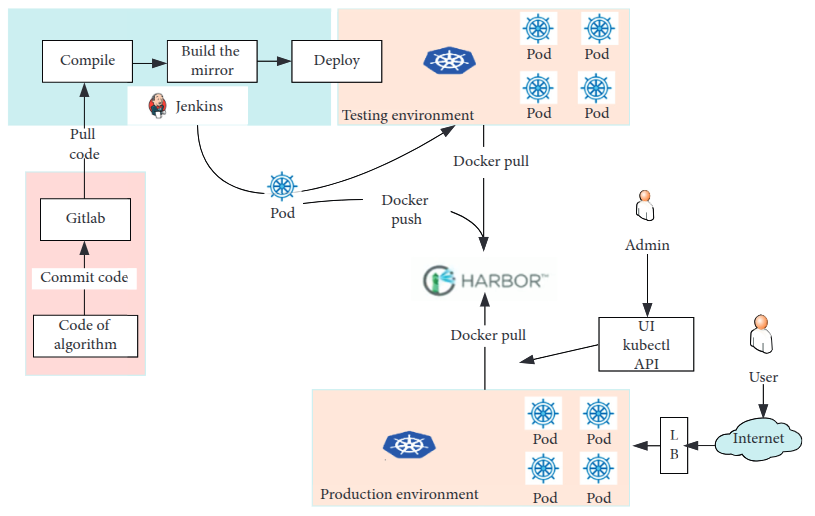
CI/CD Components
- Kubernetes (K8s)
- 컨테이너화된 애플리케이션을 자동 배포, 확장, 관리하는 도구
- 클러스터링 및 리소스 분배를 최적화하여 서비스의 가용성 유지
- Jenkins
- CI/CD 프로세스를 자동화하는 웹 기반 플랫폼
- 코드 작성 → 빌드 → 테스트 → 배포 과정을 자동화
- GitHub, GitLab 등의 코드 저장소와 연동하여 최신 코드 자동 배포
- Harbor
- Docker 이미지를 관리하는 프라이빗 저장소
- 보안 강화를 위한 RBAC(Role-Based Access Control), LDAP 연동
- 네트워크 최적화 및 확장성 제공
- Pipeline
- Jenkins의 공식 플러그인으로, CI/CD 프로세스를 단계별로 정의하고 자동 실행
- 수동 배포 없이 사용자 정의 자동화 프로세스 구축 가능
CI/CD Process
- 개발자가 코드 작성 → GitLab에 푸시
- Jenkins가 GitLab에서 코드 가져오기
- Jenkins가 코드 컴파일 및 빌드 진행
- 빌드된 Docker 이미지를 Harbor 저장소에 업로드
- Docker가 Harbor에서 이미지를 가져와 프로덕션 환경에 배포
- Kubernetes(K8s)가 컨테이너 오케스트레이션 수행
- Pod(가장 작은 단위의 컨테이너 그룹) 생성
- Pod가 자동으로 코드 빌드, 이미지 푸시 수행
- 작업 완료 후 Pod는 자동 삭제 및 리소스 해제
- 로봇 애플리케이션 개발자는 Harbor에서 이미지를 가져와 원하는 환경에 배포 가능
'etc' 카테고리의 다른 글
| How to set log level (0) | 2025.02.04 |
|---|---|
| How to register member functions of other classes as callback functions in ROS2 (0) | 2025.01.22 |
| colcon graph (0) | 2025.01.16 |
| Python Package Offline Install (0) | 2024.01.18 |
| Fix client coordinates and set camera projection in Gazebo (0) | 2023.11.20 |


