[리버스 프록시 서버로 사용하기]
- 준비물 : 리버스 프록시 서버 1대, 웹 서버 2대
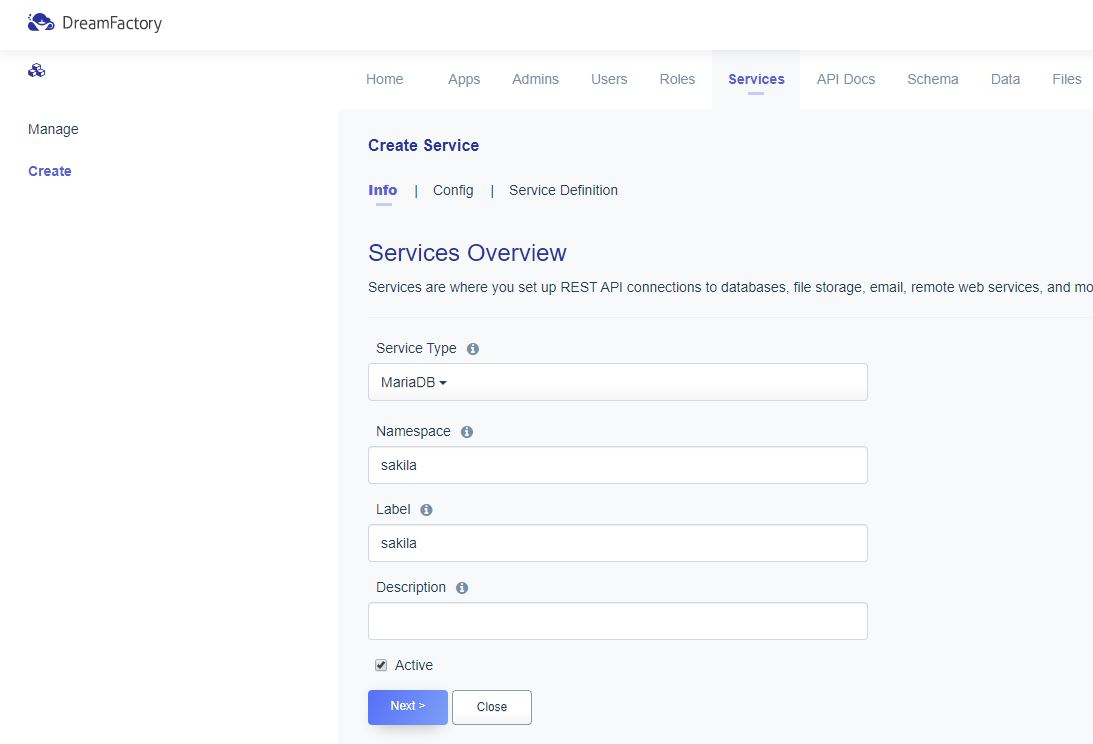
먼저 리버스 프록시서버로 사용 할 서버 1대(www.tmdahr1245.com)에 nginx를 설치해주고,
웹서버는 외부에서 접근하지 못하도록 사설IP 192.168.152.129를 사용하는 서버에 3000번과 4000번으로 각각 웹서버를 열었다.


/etc/nginx/nginx.conf 파일을 서버 상황에 맞게 적절히 세팅한다.
나는 include /etc/nginx/sites-enabled/*; 이부분을 주석처리 했다.
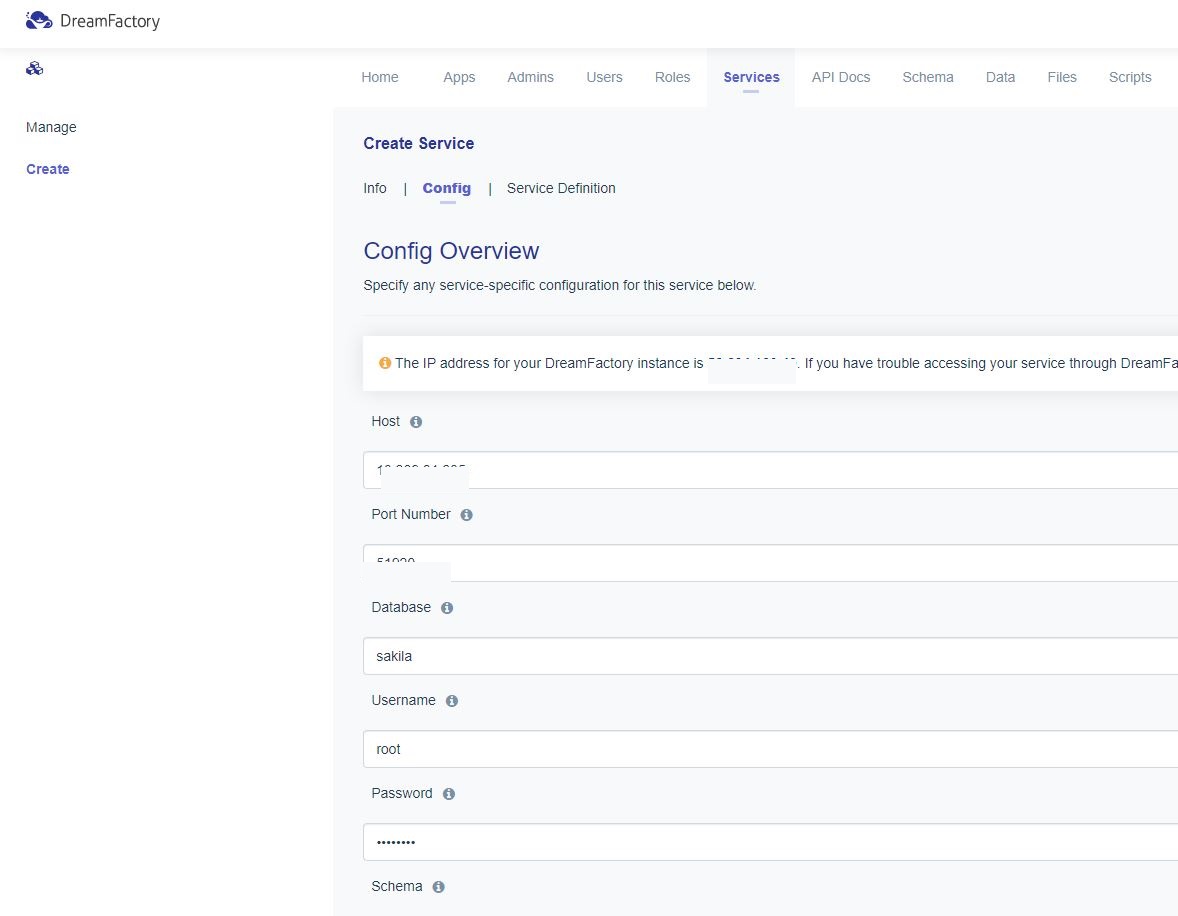
이후 nginx가 설치된 서버에 /etc/nginx/conf.d/web.conf 라는 파일을 생성하고 아래 설정값을 넣어준다.

위 설정값은 http://www.tmdahr1245.com/a 라는 URL로 요청이 들어오면 http://192.168.152.129:3000/a 로 request 패킷을 전송하겠다는 설정이다.
http://www.tmdahr1245.com/a의 엑세스로그에는 정상적으로 로깅이 되며,
request는 웹서버(192.168.152.129:3000, 192.168.152.129:4000)에서 처리하여 response를 다시 http://tmdahr1245.com/a 로 전달하고,
해당 리버스 프록시 서버에서 클라이언트에게 response를 준다.






[로드밸런서로 사용하기]
- 준비물 : 로드밸런서용 서버 1대, 웹 서버 2대


로드밸런서 역할을 할 서버 1대(www.tmdahr1245.com)에 nginx를 설치해주고, 동일한 기능의 웹서버 2대를 준비한다.
이후 nginx가 설치된 서버에/etc/nginx/conf.d/web.conf라는 파일을 생성하고 아래 설정값을 넣어준다.

위 설정값은http://www.tmdahr1245.com/a라는 URL로 요청이 들어오면,
http://192.168.152.129:3000/a, http://192.168.152.129:4000/a로 request 패킷을 번갈아 전송하겠다는 설정이다.
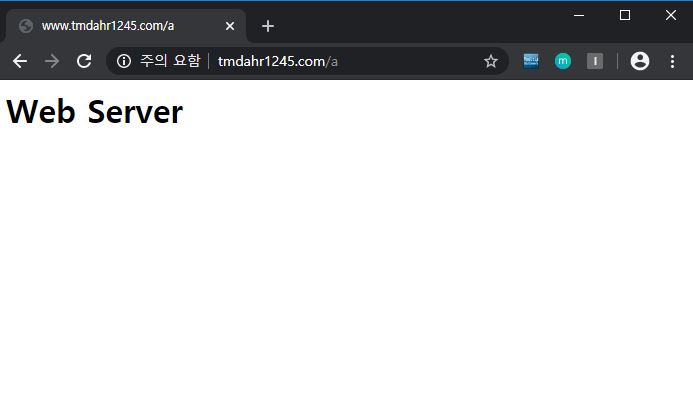


실제로 client는 계속 www.tmdahr1245.com/a에 접속을 하지만, www.tmdahr1245.com에서는 192.168.152.129의 3000번 포트 웹서버와 4000번 포트 웹서버로 번갈아 요청이 가는것을 확인할 수 있다.
로드밸런싱 알고리즘
- 기본적인 로드밸런싱 알고리즘을 upstream 옵션을 통해 설정하고 이외에도 여러 옵션들이 있다.
| 로드밸런싱 알고리즘 | 설명 | upstream 옵션 |
| Round Robin | request 순서대로 번갈아 처리 | default |
| Weighted Round Robin |
각각의 서버에 가중치를 정하고, 가중치대로 request를 처리 |
weight = n |
| IP Hash |
client의 ip를 해싱하여 특정 client는 항상 동일한 서버로 연결 |
ip_hash; |
| Least Connection | 요청이 들어온 시점에 가장 연결이 적은 서버로 연결 | least_conn; |
http://nginx.org/en/docs/http/ngx_http_upstream_module.html#upstream
'리눅스' 카테고리의 다른 글
| Linux Signal List (0) | 2021.06.10 |
|---|---|
| How to use ctags (0) | 2020.11.04 |
| How to kill a network session in Linux (0) | 2020.03.19 |
| Remote control using SPICE protocol on the web (0) | 2019.11.27 |
| How To Use apt-get (0) | 2016.10.17 |