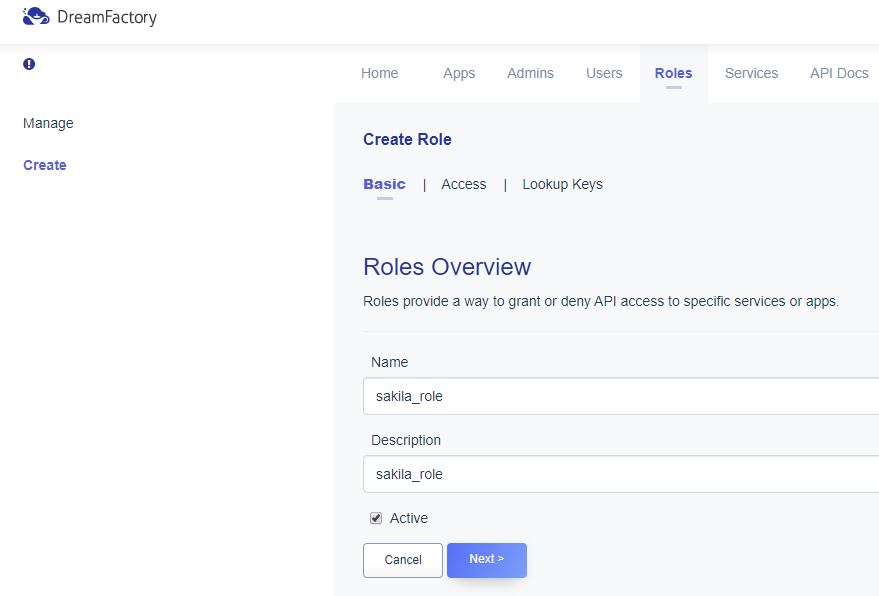
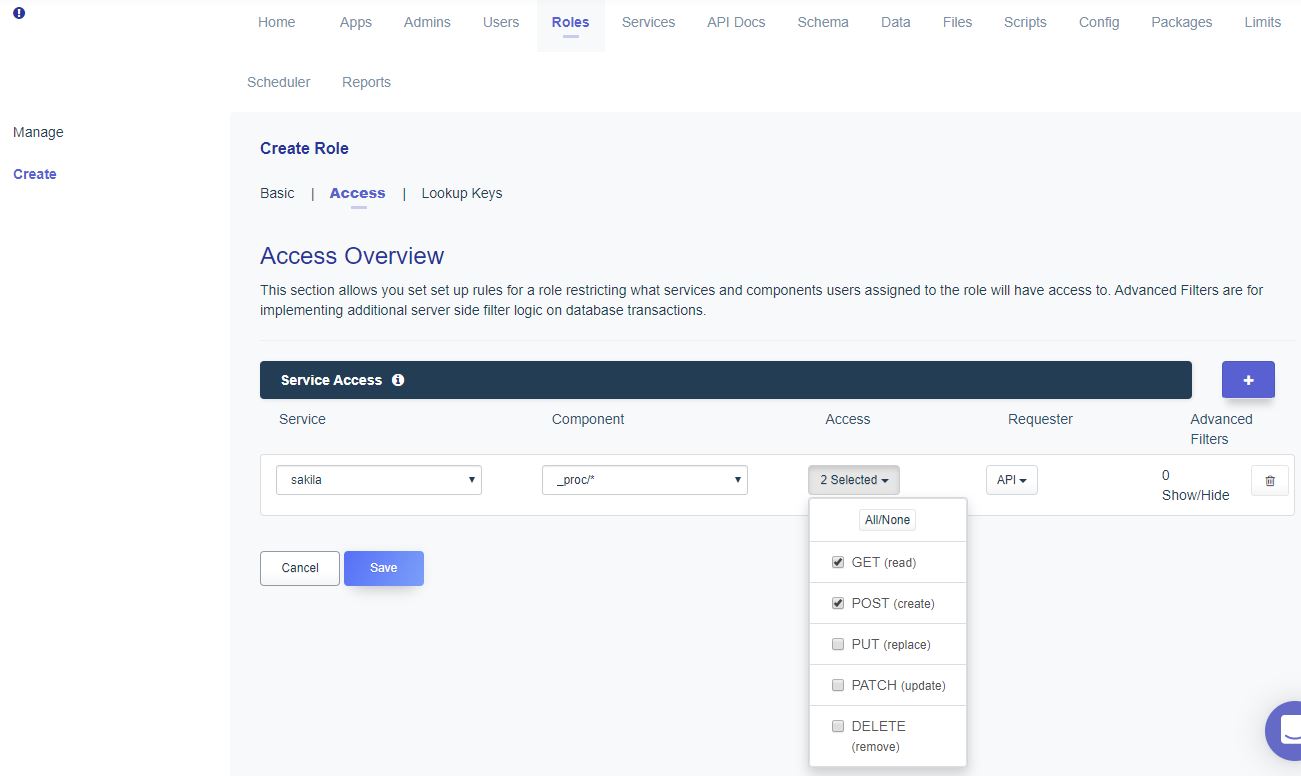
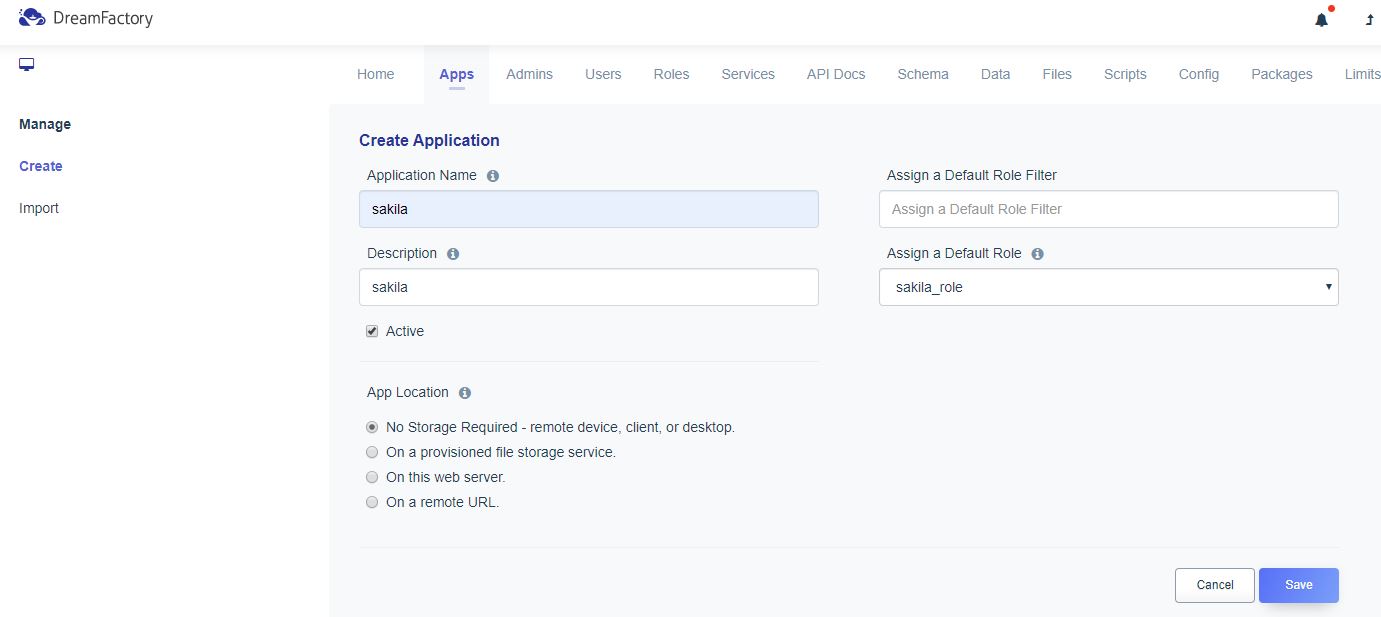
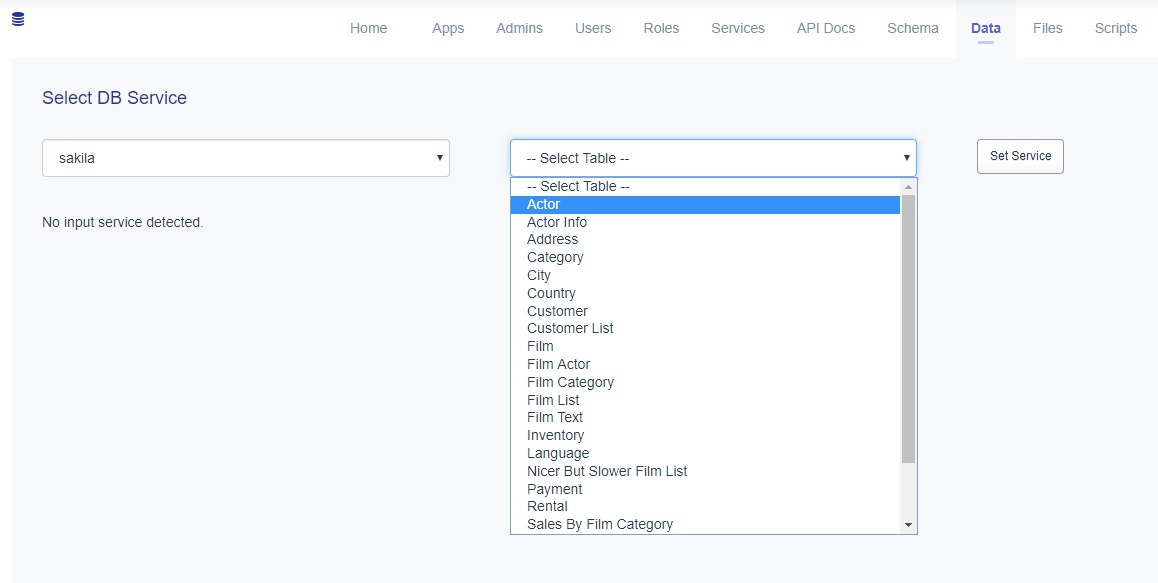
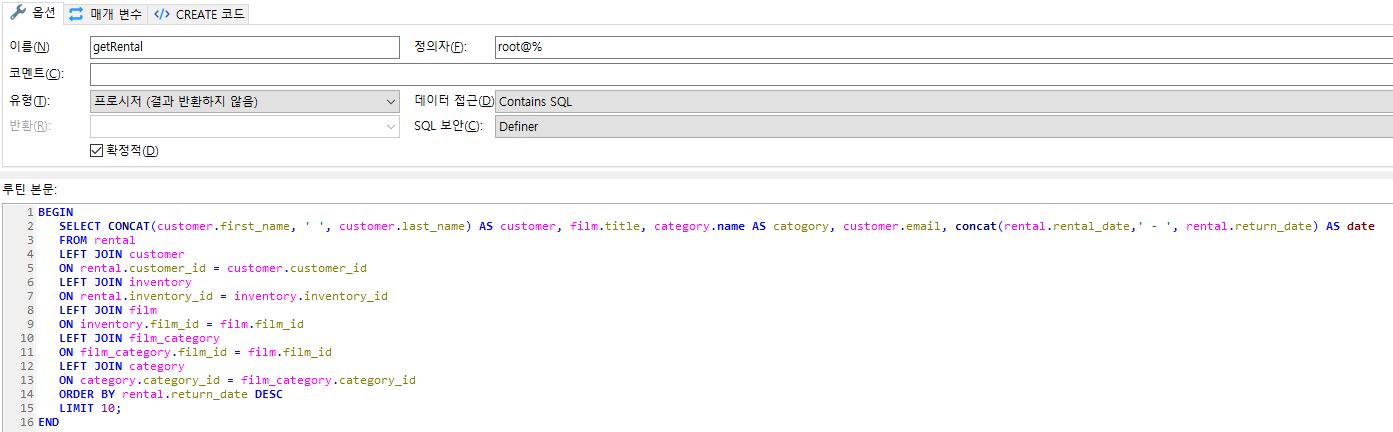
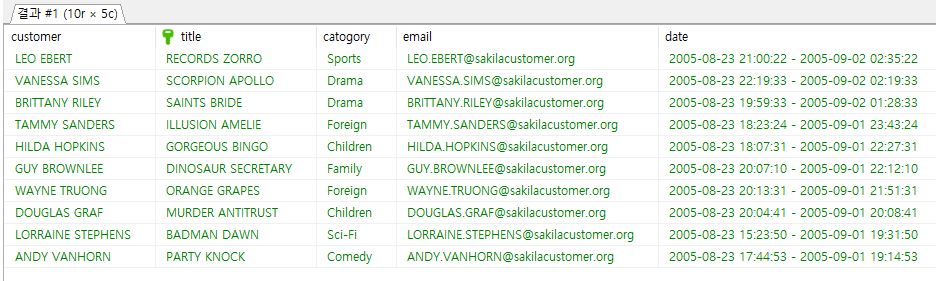
Scalable and Hardware-independent Firmware Testing via Automatic Peripheral Interface Modeling(Usenix 2020)
Processor-Peripheral Interface Modeling
펌웨어를 MCU의 펌웨어로 국한
[Open Challenges]
1. Hardware Dependence
하드웨어 의존은 퍼징하는데 delay를 만들고, 병렬처리를 하는데 한계가 존재.
즉, 병렬 퍼징이 힘들다.
2. Wide Range of Peripherals
최근에는 펌웨어의 에뮬레이션 기반 퍼징만 제안이 있어왔음.
그러나 에뮬레이팅된 MCU를 생성하는것은 비 실용적이고, 존재하는 에뮬레이터는 MCU를 지원하지 않음.
때문에 보통 퍼징이나 테스팅을 위해 에뮬레이터를 커스터마이징함.
이른 에러도 많고, MCU의 종류가 많아 현실적으로 힘든 부분이 존재.
3. Diverse OS & System Design
기존의 퍼저들을 펌웨어 퍼징에 적용하기 어렵다.
MCU는 일반적인 OS(Linux)가 아닌 MCU를 위해 설계된 OS를 사용.
4. Incompatible Fuzzing Interface
펌웨어의 모든 인풋은 다양한 종류의, 자신만의 convention을 가진 peripheral을 통해 들어옴.
그래서 일반 퍼저들의 인풋 인터페이스는 MCU 펌웨어에 부적절.
[Processor-Peripheral Interfaces]
펌웨어는 직접 off-chip에 접근할 수 없기 때문에 On-chip peripheral만 다룸.
레지스터와 인터럽트를 통한 peripheral I/O 인터페이스를 다룸.
DMA를 통한 peripheral I/O 인터페이스는 제외.
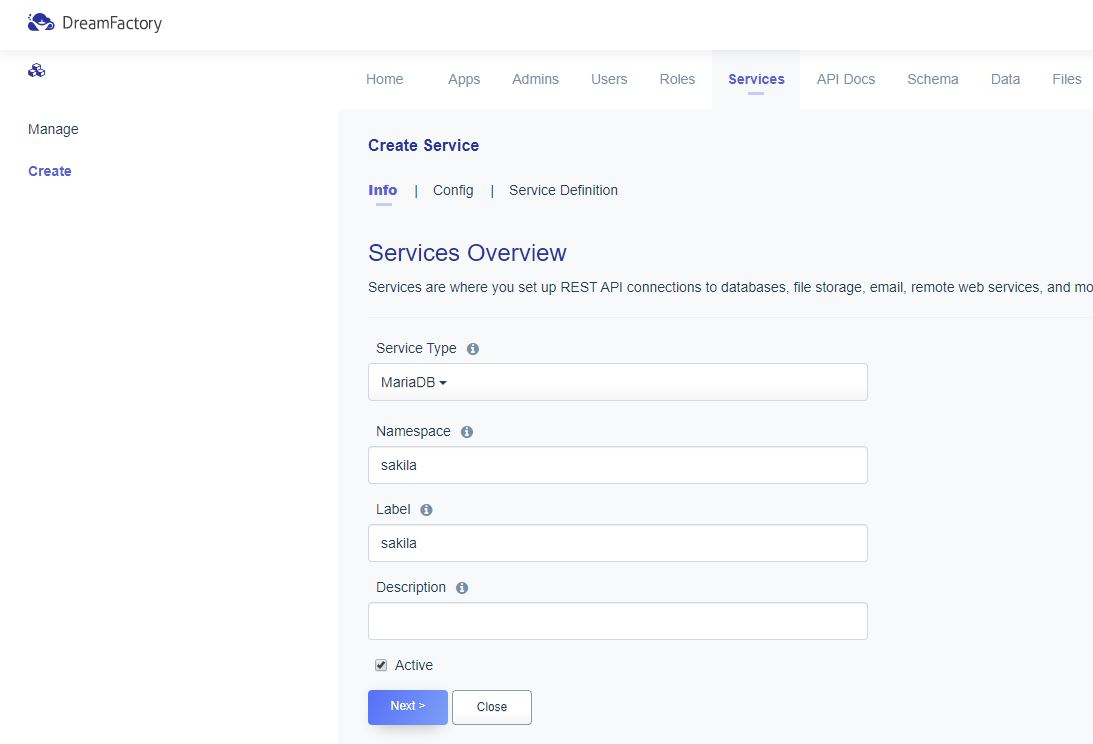
[P2IM]
1. Abstract Model
- P2IM에 접근할때 펌웨어가 따르는 컨벤션이나 패턴들을 MCU Device 데이터 시트 또는 프로세서 Doc를 통해 수집.
- 이 단계는 전문가들에 의해 이루어지는 오프라인 수작업 단계(only manual step in P2IM).
- 일단 ARM Cortex-M 프로세서만 available.
- 다른 아키텍쳐를 위한 abstract model을 정의하는건 미리 정의된 템플릿이 있기때문에 많은 노력없이도 가능.
- 이 단계는 MCU 아키텍쳐별로 한번만 이루어지는 과정이고, 대부분의 MCU는 동일한 아키텍쳐(ARM Cortex-M)를 사용.
- first, peripheral 레지스터를 4개로 분류후, 각 레지스터별 엑세스 패턴과 엑세스 핸들링 방법을 제공.
* Control Register(CR)
* Status Register(SR)
* Data Register(DR)
* Control-Status Register(C&SR)
- second, peripheral을 대신해 에뮬레이터가 인터럽트할 방법을 정의.
* ex) 인터럽트가 인풋이 준비되었다는 신호를 펌웨어에 보내면, ISR(Interrupt service routine)이 동작하고, 데이터 레지스터에 있는 인풋을 읽음
* 인터럽트 전략은 간단한 방식인 Round-Robin.
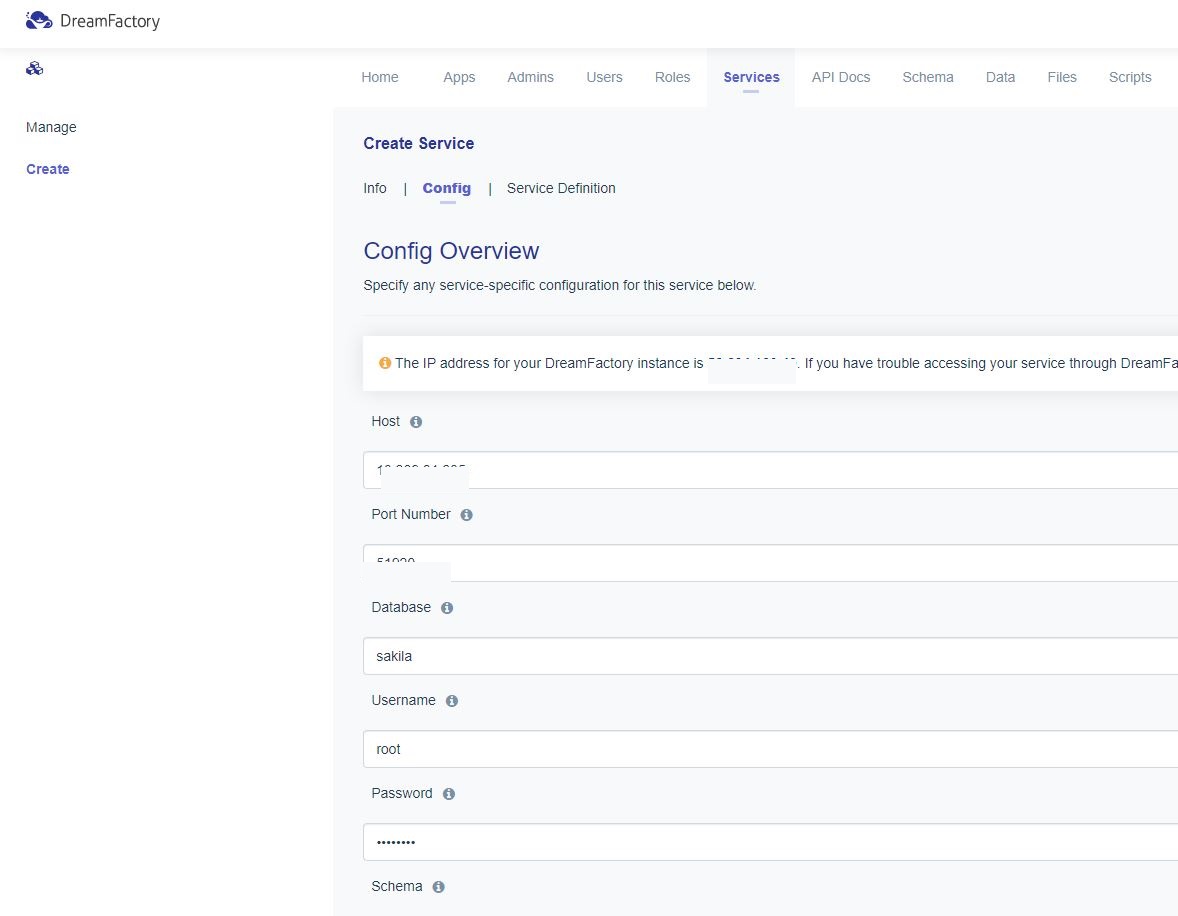
2. Model Instantiation
- abstract model을 인스턴스화 하여 분석할 펌웨어를 완전한 모델로 생성하는 단계.
- firmware-specific한 정보를 자동으로 추론.
- deterministic하고 repeatable한 작업.
- 인스턴스화 된 모델은 펌웨어 특화된 정보를 포함.
1. 식별된 memory mapped 레지스터, 메모리 위치, 타입
2. 레지스터 타입별 엑세스 핸들링 전략.
3. enabled 인터럽트 전략.
- peripheral config 관련정보는 불포함.
- peripheral을 에뮬리이팅 하지않은 에뮬레이터에서 펌웨어를 실행.
- 펌웨어가 Processor Peripheral Interface에 접근할때 계속적으로 모델을 인스턴스화 함.
[Implementation]
QEMU + AFL
AFL은 유저모드 에뮬레이션만 지원하는데, AFL을 QEMU의 full system 에뮬레이션 모드에 연결되도록 브릿지 해야함.
TriforceAFL은 full system 에뮬레이션을 지원하기 때문에, TriforceAFL의 코드를 통해 AFL을 QEMU에 연결.
퍼저에 의해 생성된 인풋은 DR(Data Register)를 통해 펌웨어에 전달.
QEMU를 통해 코드커버리지 정보를 수집후 퍼저에 전달.
[Unit Test on MCU Peripheral & OS]
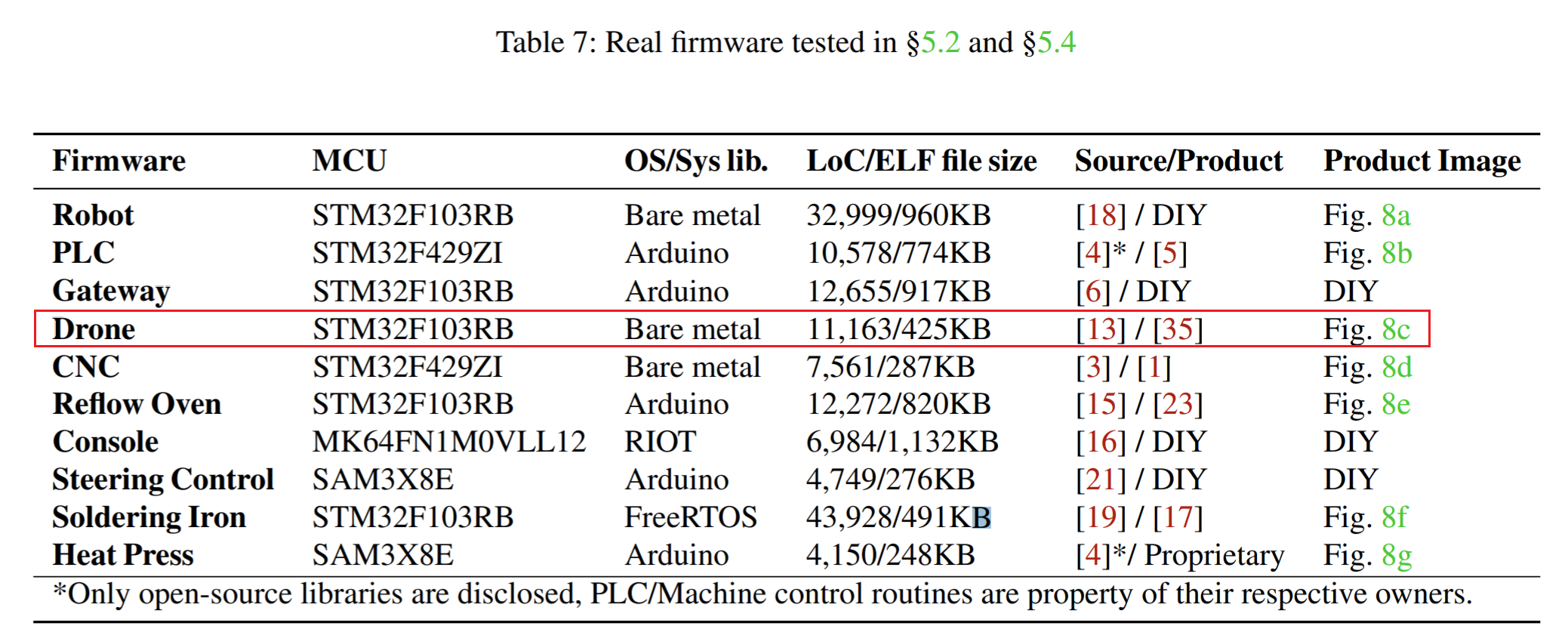
On-Chip에서 가장 popular한 8개의 Peripherals.
OS/system libraries(NuttX, RIOT, and Arduino)
SoCs (STM32 F103RB, NXP MK64FN1M0VLL12, and Atmel SAM3X8E)
다른 유사한 시스템을 실행하는 컴퓨터를 사용하는 아이디어는 자원을 유틸화 하고 테스팅 하는 목적에 유용하다고 일찍이 인식댐.
ibm, vmware, xen등 최근에 기업에서 여러 가상시스템기술을 움직이고있음
x86 가상화 확장
- x86은 가상화 하기 어려운데
- 가상화의 중요성을 인식하고 인텔,amd에서 가상화를 좀더 쉽게 만들기위해 x86에 extension들을 추가함
- 이 extension들은 서로 호환이 잘 안되서 그들은 서로 반드시 유사해야했음
- 새로운 guest operating 모드 : 시스템이 선택적으로 특정한 명령이나 레지스터접근을 요청하는것 말고는 일반적인 운영모드의 권한을 가지는 guest 모드로 프로세서가 switch 할수있다.
- 하드웨어 상태 switch : guest모드로 switch할때, 하드웨어는 프로세서 운영모드에 영향을 주는 control 레지스터를 switch한다.
- 종료 사유를 기록하기 : guest모드에서 다시 호스트 모드로 switch가 발생하면 하드웨어는 switch하는 이유를 기록해서 소프트웨어가 적당한 action을 취하도록 할수있다.
일반적인 kvm 구조
kvm은 /dev/kvm에 device node를 열어서 가상머신을 만듬
게스트는 자신의 메모리를 가지고 userspace와 분리댐
가상 CPU는 스스로 스케쥴링 못함
/dev/kvm
kvm은 꽤 전형적인 linux character device로 구성댐
새로운 가상머신 만들고, 가상머신에 메모리 할당, 가상cpu 레지스터 읽고쓰기, 가상cpu로 인터럽트 삽입, 가상 cpu실행
user 메모리처럼 커널은 guest address 공간에 형성하기위해 비연속적인 페이지를 할당함.
커널모드 유저모드 이외의 새로운 실행모드인 guest 모드가 추가댐(Figure 2 -> guest mode execution loop 설명)
명령어 셋의 차이점 조화하기
x86 명령어셋과 달리 하드웨어 가상화 extensions는 표준화되지 않음, 인텔과 amd는 명령어, 문법 모두 다름
kvm은 커널모듈을 통해 이러한 차이점을 조절함
Memory Management Unit 가상화
x86은 사용자가 볼수있는 가상 주소를 bus에 접근하기위해 사용되는 물리주소로 변환하는 가상 메모리 시스템을 제공함 => MMU. [MMU의 구성]
virtual <-> physical 변환하는 radix tree
시스템에 변환오류를 알리는 mechanism
page table lookup 을 가속화하는 단일 캐시
독립적인 주소공간을 공급하기 위해 translation root를 변환하는 명령어
TLB(Translation Lookaside Buffer)를 관리하는 명령어
MMU는 한가지 레벨에서의 변환(guest-virtual => guest-physical)은 제공하지만, 가상화가 요구되는 두가지 레벨(guest-physical => host-physical)에서의 변환은 불가하다.
이에대한 근본적인 해결책은 guest가 제공한 원본 page를 가지고 하드웨어 interaction을 에뮬레이션 하는동안, guset-virtual에서 host-physical로의 변환을 인코딩하는 분리된 page table을 실제 MMU에 나타내는 하드웨어 가상화 능력 사용하는것이다.
shadow page table 생산은 증가세이다. 그것은 비워지고 있으며, 변환 실패가 host에 기록되어 missing entry가 추가되었다.
guest page table은 원본 메모리에 존재하기 때문에 shadow page table과 동기화하는것은 어렵고 문제가 된다.
4.1 가상 TLB 실행
- kvm에서 shadow page table의 초기버전은 성능을 희생하여 코드내 많은 버그를 줄이는 복잡하지 않은 방법을 사용했다.
- 이러한 방법은 guest가 tlb 관리 명령어를 tlb를 동기화 하는데 사용해야한다는 사실에 의존했다.
- 그러나 tlb 관리 명령어의 대부분은 컨택스트 스위칭이 대부분이었고, 이는 모든 tlb를 무효화했다.
- 이것은 shadow page table이 tlb를 refill 하는것보다 좀더 많은 비용을 요구했기 때문에, 다양한 프로세스들의 작업량에 많은 고통을 받는다는것을 의미했다.
4.2 가상 MMU 캐싱
- guest system의 성능을 개선하기 위해, 가상 mmu 실행은 page table이 컨택스트 스위칭을 통해 캐시되도록 하는것을 가능하도록 함으로써 강화되었다.
- 이것은 code complexity가 증가하는 대신 막대한 성능 증가를 실현했다.
- guest의 write에 대한 notification을 받기위해 guest page table에 쓰기권한을 protect로 설정했으나, 이것은 추가적인 연쇄적 요구사항을 만들어 이를 충족시켰고, kvm 컨택스트 스위칭 성능이 현재는 적절하게 되었다.
[요구사항]
1. 각각의 guest page를 참조하는 모든 writable 변환의 reverse mapping이 유지되어야한다.
2. x86 명령어 인터프리터를 사용하는 access를 에뮬레이팅 함으로써, 우리는 미리 guest memory와 shadow page table에 미치는 영향을 알 수 있다.
3. guest는 page table page를 kvm에게 알리지않고 일반 page로 재활용한다.
I/O 가상화
VMM은 실제 s/w, h/w에서 처럼 pio(Programmed I/O), mmio(memory mapped I/O)를 에뮬레이팅 하고 가상 하드웨어에서 인터럽트를 받아 시뮬레이션 할 수 있어야함
5.1 guest측 I/O 명령어 가상화
- pio를 trap하는것은 복잡하지 않고, mmio를 trap하는것은 꽤 복잡함
- kvm에서 I/O 가상화는 user 영역에서 진행됨
- kvm은 user 영역이 guest로 인터럽트를 보내는 메커니즘을 제공함
5.2 host측 가상 인터럽트
- guest가 인터럽트를 받을 준비가 되었을때 인터럽트 플래그가 set되고, guest가 준비되면 인터럽트가 보내진다.
- 이는 kvm이 x86기반의 시스템에 있는 복잡한 인터럽트 컨트롤러들을 에뮬레이팅 하도록한다.
5.3 Framebuffer 가상화
- Framebuffer는 memory-mapped I/O 장치의 중요한 부분
- 전형적인 mmio와 다른 특성(대역폭, 메모리 등가)
- kvm은 임의의 주소에 비 mmio 메모리를 맵핑하도록 함, 이것은 물리적으로 메모리를 alias하도록하는 VGA windows에 포함됨
- 또한 framebuffer의 변화를 기록함으로써, display window가 점차 최신화 될수있음
Linux Intergration
리눅스로 통합되는것은 kvm에 중요한 이익을 줌
개발자 측면에서 커널 내 존재하는 기능을 재사용하도록 많은 기회를줌
사용자 측면에서 기존에 있던 리눅스의 프로세스 관리 인프라(top, taskset, kill)를 재사용 하도록함
Live Migration
가상화를 진행하는 이유중 하나
이는 한 guest를 한 host에서 다른 host로 쉽게 옮길 수 있도록함
병렬적으로 guest 메모리를 타겟 호스트로 복사함
guest page를 복사 후 수정이 발생하면 다시 복사함
마지막에 kvm은 page 로그를 제공하는데 이는 마지막 호출 후 수정된 페이지의 비트맵을 user 영역에 제공함
80년대 자동차 산업에서 처음 ECU가 등장하였고, 프로그램 크기와 complexity의 관점에서 ECU 내부의 소프트웨어는 간단하계 설계되었다. 현재는 자율주행의 완성도가 점점 높아지고 있으며, telematics, 인포테인먼트, IoT 장비 등등 많은것들이 차량 내부에 설치되고있다. 그러나 소프트웨어들이 많아질수록 다양한 OEM에서 다양한 규격의 소프트웨어들이 제작되었고, 제각각인 소프트웨어에 대한 표준이 필요했는데 그게 바로 AUTOSAR이다. 2002년 AUTOSAR가 처음 소개되었고, 차량 소프트웨어 개발의 관점에서의 기준 제시였다. 그러나 AUTOSAR 위에서 개발된 소프트웨어는 소프트웨어 lifecycle 내에 소프트웨어 업데이트가 이루어지지 않는다는 전제가 깔려있고, 최근에 개발되는 소프트웨어들은 빈번한 업데이트가 필요하기 때문에 Classic AUTOSAR는 맞지않다. 이는 Classic AUTOSAR가 구식이라는 이야기는 아니고, 자율주행과 같은 미래시대의 needs를 충족시키기 위한 다른 기준의 필요성 정도이다. 어쨋든 이러한 needs를 충족시키기 위해 나온 새로운 기준이 Adaptive AUTOSAR이다.
[Adaptive AUTOSAR의 필요성]
Advanced Driver Assistance System
ADAS는 자율주행의 핵심기술로 라이다, 레이더, 고성능 카메라와 같은 센서들을 기반로 동작한다. 사실상 다이나믹 통신, 유연하고 안전한 플랫폼, 빠른 데이터 전송과 프로세싱등을 제공하는 Adaptive AUTOSAR를 요구한것은 자율주행이라고 할 수 있겠다. 자율주행은 신호등, 다른 차량과 통신을 하고, 센서와 카메라를 통해 얻은 차량 외부 환경에 관련된 데이터를 가지고 핸들을 조향하고 속도를 줄이는등 차량을 조작한다. 라이다, 레이더와 같은 센서를 통해 얻은 데이터는 실시간으로 ECU에 전송되어 빠르게 처리되어야한다. 빠른 차량내부 통신을 위해서 기존의 통신 프로토콜인 CAN, LIN, Flexray 등은 충분한 속도를 내지 못하고 이더넷, SOME/IP와 같은 프로토콜이 도입되어야한다.
Vehicle Architecture
센서와 직접 연결된 기존의 ECU와 다르게, 새로운 Domain Controller Architecture는 자율주행에서 새로운 트렌드가 되고있다. 분리된 컨트롤러대신 이 컨트롤러는 Body Control, 인포테인먼트, 파워트레인 등 각각의 도메인들에 할당된다. 전기차의 경우 충전소와 차량간의 통신은 유일하고 안전해야 한다. Classic AUTOSAR는 이러한 요구조건에 맞게 설계되지 않았다.
Firmware-Over-The-Air Update(FOTA)
OTA란 새로운 소프트웨어, 업데이트 등을 무선 네트워크를 통해 배포하는것인데 FOTA는 펌웨어를 무선으로 다운받아 업데이트 한다는 것이다. Classic AUTOSAR는 FOTA를 제공한다. 그러나 ECU 내부 각각의 어플리케이션을 업데이트할 수는 없고, 이는 Classic AUTOSAR에서 FOTA에 대한 의존성을 약화시켰다. flexible한 Adaptive AUTOSAR는 새로운 주안점을 가지고 소프트웨어를 업데이트하고 확장시켰다.
Classic AUTOSAR
Adaptive AUTOSAR
CAN, LIN, Flexray
이더넷, SOME/IP
임베디드 functionality
고성능 연산능력 강화된 functionality
엔진 컨트롤, 브레이크 시스템, 에어벡
OTA, 센서 데이터 프로세싱
런타임에 업데이트는불가능
실시간 OTA 업데이트 가능
모든 ECU 코드 변경
ECU내 각각의 어플리케이션을 수정
유연성 낮음
유연성 높음
C언어 기반
C++ 기반
OS 필요없음
POSIX OS
static Configuration
dynamic Configuration
[Classic AUTOSAR와 Adaptive AUTOSAR의 아키텍쳐]
[두 AUTOSAR는 공존 가능한가?]
위에서도 언급했듯이 Adaptive AUTOSAR는 Classic AUTOSAR의 대체가 아니고 자동차 생태계에서 상호공존을 의미한다. 두 플랫폼 모두 각기다른 문제에 대한 솔루션이며, 이것들의 공존은 높은 가치를 창출한다.
위 사진은 두 플랫폼이 차량 내에서 공존하는 overview이다. CAN, LIN등의 차량 내부 프로토콜을 사용하던 Classic AUTOSAR와 달리, Adaptive AUTOSAR가 가져온 가장 큰 변화는 이더넷 프로토콜이다.
그렇다면 Adaptive와 Classic ECU는 어떻게 통신할까? 첫번째 시나리오는 gateway ECU이다. Classic ECU는 게이트웨이로써의 역할을 하고, BUS 시스템에서 Adaptive ECU가 읽을수 있는 서비스로 신호를 패킹한다. 다만 포맷에대한 변화는 필요하다. Classic ECU는 단지 신호기반이고, 신호를 서비스로 패킹할 수 없다는 또 다른 시나리오가 있다. 여기서 Classic ECU는 신호를 UDP 프레임으로 변환하고, 이를 이더넷으로 전송한다. Adaptive ECU는 UDP 프레임을 서비스로 변환하기위해 'signal to service'라는 맵핑 feature를 갖추고있다.
[AUTOSAR의 미래]
Classic과 Adaptive AUTOSAR는 상호 보완하고 공존이 가능하다. Classic AUTOSAR는 소프트웨어가 깊게 embedded된 functional ECU에 특화된 플랫폼이고, 자율주행을 실현시켜주는 미래지향적인 플랫폼이 Adaptive AUTOSAR이다. 그리고 자동차 산업에서 두 플랫폼은 모두 필요하다. 언젠가 Adaptive AUTOSAR가 ECU 소프트웨어 개발에 있어서 단독 플랫폼이 될지도 모르지만 아직 그렇게 생각하기에는 이르다.